



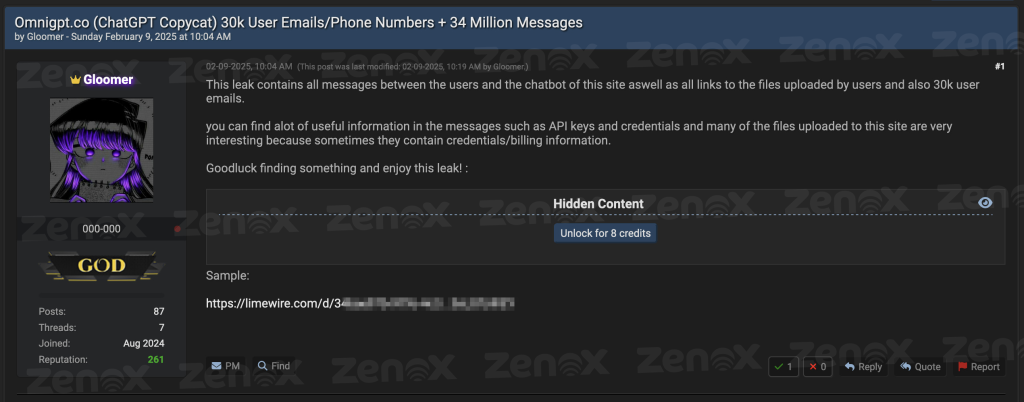
El pasado lunes (09/02), un usuario de BreachForums identificado como “Gloomer” afirmó haber comprometido OmniGPT, un agregador de Inteligencia Artificial (IA) ampliamente utilizado que brinda acceso a varios modelos, incluidos ChatGPT-4, Claude 3.5, Gemini y Midjourney.
El actor malicioso asegura haber obtenido aproximadamente 30.000 direcciones de correo electrónico, números de teléfono de usuarios y más de 34 millones de líneas de conversaciones, además de todos los enlaces a los archivos que los usuarios subieron a la plataforma. Se publicó una muestra del conjunto de datos filtrados en la misma entrada del foro.
El material completo de la filtración está disponible públicamente en BreachForums y se puede acceder a él mediante 8 créditos, una unidad de intercambio interna del foro que los participantes utilizan para adquirir materiales filtrados y otros contenidos restringidos.
Estructura de la Filtración
El equipo de Threat Intelligence de ZenoX llevó a cabo una investigación exhaustiva del material filtrado. El paquete inicial consistía en un archivo ZIP de 534 MB que, al descomprimirse, reveló aproximadamente 1,8 GB de datos distribuidos en cuatro archivos diferentes. El archivo «Files.txt» contenía todas las URLs de los archivos que los usuarios habían subido a la plataforma, exponiendo potencialmente documentos confidenciales, código propietario y otros materiales sensibles. El archivo «messages.txt», el más voluminoso del conjunto, contenía más de 34 millones de líneas de conversaciones entre los usuarios y los distintos modelos de IA, incluyendo información potencialmente sensible.
Los dos archivos restantes incluían información personal de los usuarios, como direcciones de correo electrónico, identificadores únicos y números de teléfono, creando un catálogo completo que podría utilizarse para ataques dirigidos o campañas de ingeniería social.
Análisis Técnico
Para comprender la magnitud y las implicaciones de la filtración, el análisis del material filtrado se dividió en dos partes. Se desarrolló un script en Golang que incorporó ambos enfoques, cada uno con sus propias limitaciones y desafíos técnicos.
1. Detección de Credenciales
La primera etapa del análisis se centró en la identificación de posibles credenciales y tokens de acceso. Se empleó una lista de 87 patrones de expresiones regulares (regex) que abarcaba claves de AWS, tokens de acceso de GitHub, Stripe y otras credenciales utilizadas en el desarrollo de software. El análisis reveló diversos tipos de credenciales, destacándose:
- 206 tokens de Hugging Face, que potencialmente permitirían el acceso a modelos de machine learning propietarios y datos de entrenamiento. La alta incidencia sugiere un uso significativo de la plataforma para desarrollo de IA.
- 369 tokens JWT, con un alto nivel de riesgo debido a la naturaleza de la información que pueden contener y su posible uso para la autenticación en varios sistemas.
- En el entorno en la nube, se identificaron 38 claves de AWS Access Key y 46 cuentas de servicio de Google Cloud Platform. La presencia de estas credenciales es especialmente preocupante por el amplio acceso que pueden proporcionar a recursos críticos de infraestructura.
- 28 claves de Stripe (14 públicas y 14 secretas) fueron encontradas, lo que indica la exposición de sistemas de pago y procesamiento financiero.
| Tipo de Credencial | Cantidad |
| JWT token | 369 |
| Hugging Face Access Token | 206 |
| Google (GCP) Service-account | 46 |
| AWS Access Key ID | 38 |
| Stripe Publishable Key | 25 |
| Discord client secret | 15 |
| AWS Secret Access Key | 14 |
| Shopify token | 14 |
| Stripe Secret Key | 14 |
| Asymmetric Private Key | 13 |
| GitLab Personal Access Token | 11 |
| GitHub Personal Access Token | 3 |
| GitHub Fine-grained PAT | 2 |
| SendGrid API token | 2 |
| Slack Webhook | 1 |
| Adobe Client ID | 1 |
2. Análisis Sectorial
La segunda etapa se enfocó en el análisis sectorial de la filtración, basándose en las 1000 mayores empresas brasileñas para mapear el impacto en diferentes segmentos de mercado. Después de una búsqueda simple por cadenas de texto, se detectaron 232.000 referencias a organizaciones incluidas en ese ranking. Se eligió este método por su simplicidad y eficiencia operativa, evitando la implementación de técnicas más complejas como Named Entity Recognition (NER) y métodos avanzados de Procesamiento de Lenguaje Natural (NLP). Aunque estas técnicas podrían aportar mayor precisión, se decidió no utilizarlas para agilizar el análisis inicial.
El uso de técnicas de NER, por ejemplo, podría diferenciar el nombre de una empresa de su uso como adjetivo común o identificar menciones indirectas y referencias contextuales a organizaciones. Sin embargo, el análisis optó por un algoritmo más directo, dando prioridad a una aplicación rápida, con ajustes y refinamientos que se llevarían a cabo en etapas posteriores.
Para disminuir la cantidad de falsos positivos y refinar los resultados, se aplicó una técnica de filtrado semántico y contextual basada en los siguientes criterios:
- Nombres Genéricos o Comunes: Empresas cuyo nombre representa términos de uso frecuente en el vocabulario cotidiano o palabras que aparecen fuera del contexto empresarial.
- Siglas Cortas o Ambiguas: Empresas identificadas por siglas de dos o tres letras que pueden confundirse con otras abreviaciones técnicas o expresiones habituales.
- Palabras Polisémicas: Empresas cuyos nombres tienen múltiples significados en diferentes contextos, a menudo utilizados para designar niveles de experiencia.
Tras esta depuración, el número de menciones se redujo de 232.000 a 16.000, representando únicamente aquellas con una alta probabilidad de ser referencias corporativas legítimas.
El análisis sectorial reveló patrones interesantes sobre el uso corporativo de herramientas de IA. El sector de aseguradoras encabezó la lista con 2.139 menciones, seguido por el sector farmacéutico y de belleza con 1.886 referencias. El segmento de transporte y logística ocupó el tercer lugar con 1.755 menciones, seguido por alimentos y bebidas con 1.549 citas. El sector financiero, que combina bancos y diversos servicios financieros, totalizó aproximadamente 2.938 menciones, demostrando una fuerte dependencia de estas tecnologías.
| Sector | Menciones |
| Aseguradoras | 2139 |
| Farmacéutico y Belleza | 1886 |
| Transporte, Logística y Servicios Logísticos | 1755 |
| Alimentos y Bebidas | 1549 |
| Bancos | 1476 |
| Servicios Financieros | 1462 |
| Educación | 1021 |
| Agronegocios | 837 |
| Mayorista y Minorista | 657 |
| Petróleo y Químico | 657 |
| Bienes de Capital y Electroelectrónicos | 604 |
| Salud y Servicios de Salud | 462 |
| Cooperativas | 438 |
| Siderurgia, Minería y Metalurgia | 389 |
| Moda y Vestuario | 317 |
| Participaciones y Medios | 285 |
| Tecnología y Telecomunicaciones | 254 |
| Energía | 169 |
| Sector Inmobiliario y Construcción Civil | 140 |
| Papel y Celulosa | 42 |
| Operadoras de Planes de Salud | 33 |
| Saneamiento y Medio Ambiente | 1 |
Esta distribución sectorial sugiere que OmniGPT se ha utilizado de forma amplia para diversos propósitos corporativos, desde el desarrollo de software y la automatización de procesos hasta el análisis de datos y la atención al cliente. La importante presencia de sectores regulados, como el de seguros y servicios financieros, plantea inquietudes adicionales sobre el cumplimiento normativo y la protección de datos sensibles.
Conclusión
Estos resultados refuerzan la presencia de soluciones de IA en múltiples segmentos de negocio, pero también exponen debilidades en el manejo de datos corporativos. Cada vez más, los equipos de desarrollo y las áreas de innovación aprovechan la productividad que ofrecen los modelos avanzados; sin embargo, es fundamental adoptar buenas prácticas de seguridad. No se trata de evitar el uso de IA, sino de crear procesos que reduzcan el riesgo de filtraciones, por ejemplo enmascarando tokens y claves reales antes de enviar fragmentos de código a cualquier modelo o plataforma de asistencia.
El incidente de OmniGPT sirve como una advertencia crucial sobre los riesgos inherentes a la adopción de herramientas de IA sin controles de seguridad adecuados. Aunque estas tecnologías brindan beneficios innegables en términos de productividad e innovación, es esencial establecer un equilibrio entre agilidad y protección de datos.
La magnitud y la naturaleza de la información expuesta demuestran que el uso corporativo de IA debe ir acompañado de una estrategia sólida de seguridad. Esto no solo implica medidas técnicas de protección, sino también un cambio cultural hacia prácticas más seguras de intercambio de información.
A medida que crece la adopción de la IA, es probable que incidentes como este se vuelvan más comunes. La capacidad de las organizaciones para proteger sus datos mientras aprovechan los beneficios de estas tecnologías será un factor competitivo clave en los próximos años. El caso OmniGPT no debe verse solo como un incidente aislado, sino como un catalizador para un debate más amplio sobre seguridad y gobernanza en el uso corporativo de la inteligencia artificial.

")